Contents
Clean Architectureとは
Clean Architectureの大まかな概要
✅ Robert C. Martin(Uncle Bob)が2012年に提唱した、DBやフレークワークから独立性を確保するために複数のレイヤーに分割して設計するアーキテクチャ(👇この図が有名ですね)
.png)
✅ アプリなどのソフトウェアを実装するのに、”クラス”, “パッケージ”, “モジュール”などをどのように分割すれば『いい』のか?という問いに対する一つの回答
✅ 上記の『いい』とは以下のような性質を持っていることを指す
①テスト可能であること(Unit Test, 自動テストのこと)
②低負荷高効率で仕様変更ができること(少ない工数で機能追加やコード修正ができること)
✅ 上記の性質を獲得するために、”関心の分離(separation of concerns)による依存関係の整理“を重視している
✅ 上の図はあくまで概要であり、アプリによってはレイヤーを増やすなど調整が必要になる
依存性のルール
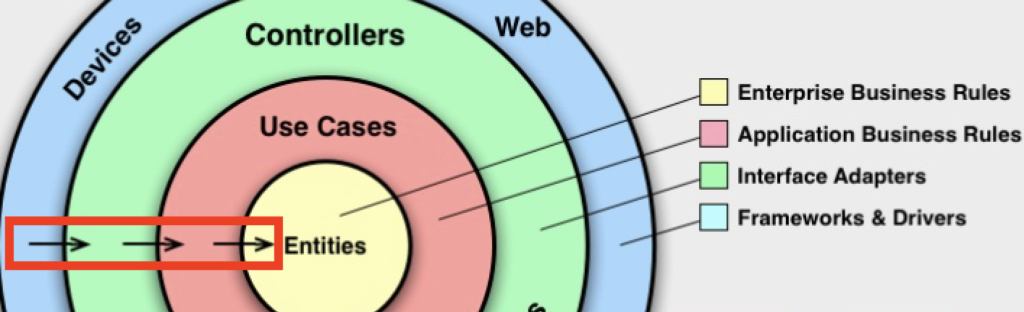
✅ “依存関係が内側に一方に向く“というルールになっている
✅ この図には以下の4つのレイヤーが定義される
- Enterprise Business Rules
- Applicaiton Business Rules
- Interface Adapters
- Frameworks & Drivers
✅ コードを層状に分離するとは
⇨実装ではなくインターフェイスに依存する、実オブジェクトは依存性注入(DI)する
✅ 矢印は外側から内側に向いており、”Controllers”は”Use Cases”に依存していると読み解くことができる
✅ どのようにレイヤーを分割するかよりも依存関係を整理するという概念の方がより重要
4つのレイヤー
✅ より内側のレイヤに行くほど抽象度が高く、より外側のレイヤーに行くほど変更頻度が高い
Enterprise Business Rules
✅ 円の一番内側にある⇨この層が『Entity』
✅ 通常ではアプリで利用するデータ用オブジェクトが入る
⇨具体的には User, Account, Productなどそのアプリで使う「名詞」を表現する
Application Business Rules
✅ この層が『Use Case』
✅ アプリ特有のビジネスロジックを表現する
✅ フレームワークやデータベースなど、外部の要素に依存しない点に注意
✅ 基本的には抽象(Entity)に依存する
Interface Adapters(Controllers, Gateways, Presenters)
✅ 外部(DBやAPI, HTTPリクエストなど)から取得したデータを次のレイヤーであるUse Casesが使いやすいように整理する(ex. DBから取得したデータをUse Casesが使いやすいようにEntityに変換する)
Frameworks & Drivers(UI, DB, Web, Devices, External interfaces)
✅ フレームワークに関するコードを配置する一番外のレイヤー
✅ 内側のレイヤーを利用するためのグルーコード(glue code)以外はなるべく書かない
⇨UIに関するコードをこのレイヤーに書く
TDDとClean Architectureを採用する理由
✅ コードをクリーンに保ちながらテストすることは重要だから
⇨アプリの規模やプロジェクトが大きくなるとビジネスロジックが散在しがちで整理が難しくなる
✅ ビジネスロジック(Entities)がUIやDBの変更の影響を受けないようにしたい
✅ Use Cases(ビジネスロジック)はDBからデータを取得し処理するため、DataSourceのコード(層の外側)に依存しがち
⇨この依存性逆転の法則により依存方向を反転させるのがClean Architectureの狙いの一つ
依存性逆転の法則
✅ アプリなどの設計を進めるにあたり以下のような問題があり、それを解決するための法則Z
✅ 問題点: 自然に実装する依存性の方向性と設計上合理的な依存の方向性が逆になってしまう
⇨ex.) UseCaseがデータを取得するため、Repositoryに依存するコードになってしまうが、Repositoryは変更される可能性が高いため、変更が発生した場合に修正点が多くなってしまう
✅ 解決方法: UseCaseがRepositoryを実装するのではなく、インターフェースに依存するようにする
⇨DI(依存性の注入)やFactory等の手法を用いることで、UseCaseがRepositoryの実装を読み込む形にする
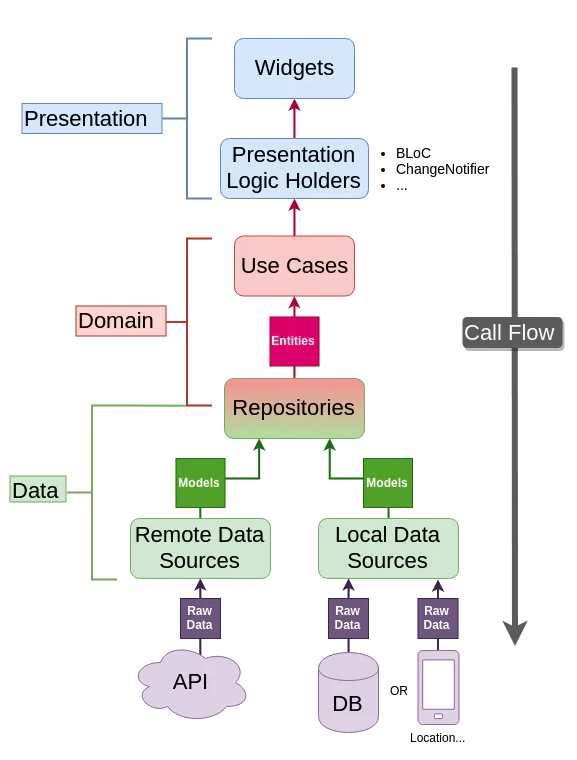
Clean Architectureの構成
フォルダ構成
👇以下のフォルダ構成が標準となっている(randomm_user_genというプロジェクトを想定)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
[~/AndroidStudioProjects/random_user_gen/lib] $ tree lib ├── core ├── features │ └── random_user_gen │ ├── data │ │ ├── datasources │ │ ├── models │ │ └── repositories │ ├── domain │ │ ├── entities │ │ ├── repositories │ │ └── usecases │ └── presentation │ ├── bloc │ ├── pages │ └── widgets └── main.dart |
Presentation
✅ Blocパターンを使う
✅ Widgetsがeventsを送って、Blocからstatesを受け取る
✅ CleanArchitectureではBlocはPresentationにあたる
Domain
✅ Use CasesとEntitiesを含む
✅ 他のレイヤーに依存しない
Repositories
Domain層とData層にまたがる
✅ ビジネスロジック(Use Cases)とデータ操作のロジックを分離して、データ操作を隠す
⇨Repositoryは永続化ストレージが何かについて関知しない
⇨Repositoryを利用するクラスはビジネスロジックに集中する
✅ Domain層にRepositoryのインターフェースが位置する
✅ Data層にRepositoryの実装が位置する
RepositoryのインターフェースがDomain層に、実装がData層にまたがる構成によってUserCaseがData層に依存することを回避する
✅ これが依存性逆転の法則を実現している
Entities
✅ ほとんど変化しない→何にも依存せず、他のオブジェクトから依存される設計となる
⇨”変化するものが変化しないもの(Entities)へ依存する”というのがCleanArchitectureの依存方向の理由になる
✅ APIから取得する情報はEntityではない
⇨Data層のDataSourceからAPIより情報を取得するが、これはEntityを継承したModelとなる
Data
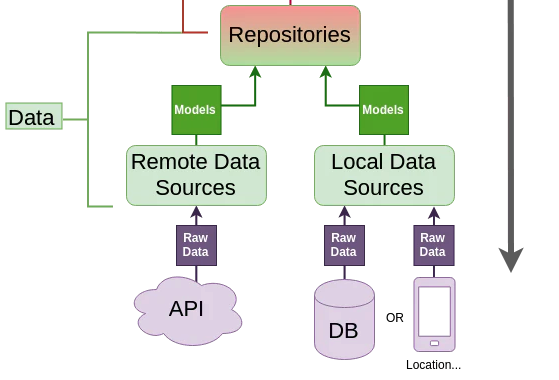
✅ Data層はRepositoryの実装とDataSourceを持つ
DataSources
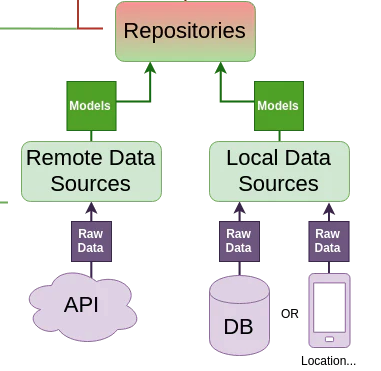
✅ DataSourcesは以下の2つがある
- APIを呼ぶRemote Data Sources
- キャッシュしたデータを読み込むLocal Data Sources
✅ DataSourcesはEntitiesではなくModelを返す→ModelはEntityを拡張した子クラス
⇨ModelはDataSourcesから受け取るJSONを処理する
⇨JSON操作に特化した機能をDomainのEntityに持ちたくないため、子クラスのModelを使う(CleanArchitecture図の中央に位置するEntityは他のレイヤーに依存せず、DataSourceが扱うデータ形式について関与しない)
✅ RepositoryはRemoteとLocalの2つのDataSourcesを組み合わせる
- RemoteDataSources: APIに対するHTTP GETリエストを処理する
- LocalDataSources: キャッシュデータを処理する(キャッシュはオフラインの時に前回通信で取得したキャッシュデータを返すというような使い方をする)
Clean Architectureを使って作るアプリの内容
✅ Random User GeneratorのAPIを呼び出し、適当なユーザーのリストを表示するだけの簡単なアプリを実装します(目的はClean Architectureを学ぶこと)
✅ 更新ボタンを設置し、ボタンをタップすると10名分のダミーユーザーデータを表示するアプリ
✅ UIの状態管理にFlutterのblocパターンを採用
まとめ
✅ Clean Architectureの本質は”依存性ルールに従って関心の分離を図る“こと
⇨そうすることで仕様変更や機能追加が容易で、テストコードが書きやすく不具合が見つけやすい設計を実現することができる



コメントを残す